> For the complete documentation index, see [llms.txt](https://nanucuyu.gitbook.io/dj-woo/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://nanucuyu.gitbook.io/dj-woo/2020/11/albert.md).
# Albert
**개인 study를 위한 자료입니다.**\
**그러다보니 내용에 잘못된 점이 있습니다.**
## 1.INTRODUCTION
논문의 시작은 2018년 Bert(Bidirectional Encoder Representations from Transformers)의 등장으로 시작된, Larger Dataset, Lager Model, Pre-trained, Fine-tuning에 대한 이야기로 시작합니다.
> Evidence from these improvements reveals that a **large network is of crucial importance for achieving state-of-the-art performance** (Devlin et al., 2019; Radford et al., 2019). It has become common practice to pre-train large models and distill them down to smaller ones (Sun et al., 2019; Turc et al.,2019) for real applications. Given the importance of model size, we ask: **Is having better NLP models as easy as having larger models?**
Large Model은 1). Memory limitations, 2). Training speed 가 단점이 됩니다. 이 2가지 점은 NLP를 개인 PC단위에서 학습할 경우, 직면하는 문제입니다.
이러한 문제를 풀기위해서는 1) model parallelization, 2) clever memory management 과 같은 한정된 자원을 잘 사용하는 방법을 사용할 수도 있습니다. 하지만, 본 논문 처럼, model architecture를 새로 디자인하는 방법을 제안합니다.
**A Lite BERT (ALBERT)** 에서 사용한 main 방법은 아래 2가지 입니다.
> The first one is a factorized embedding parameterization.
> The second technique is cross-layer parameter sharing
위 두 문장을 설명 하기 위해서는 간단히 BERT의 paramter수를 살펴 볼 필요가 있습니다.\[[1](https://github.com/google-research/bert/issues/656#issuecomment-554718760)]
* Embedding layer = 23M
* Transformer layer = 7M \* 12 = 85M
* Pooler layer = 0.6M
* Total = 110M
본 논문에서 제시하는 방법으로, 아래와 같이 parameter의 수를 약 90% 감소시킵니다.\~!
* Embedding layer = 4M (factorized embedding)
* Transformer layer = 7M (cross-layer parameter sharing)
* Pooler layer = 0.6M
* Total = 12M
이러한 model 압축에 대해서는 \[[3](https://blog.est.ai/2020/03/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%95%95%EC%B6%95-%EB%B0%A9%EB%B2%95%EB%A1%A0%EA%B3%BC-bert-%EC%95%95%EC%B6%95/)]에 잘 정리되어 있습니다.
#### 2.1 SCALING UP REPRESENTATION LEARNING FOR NATURAL LANGUAGE
Larger Dataset, Lager Model, Pre-trained, Fine-tuning 에서 large model이 performance에 중요하지만, memory limitation과 training speed에서 문제가 있다고 다시 언급합니다.
#### 2.2 CROSS-LAYER PARAMETER SHARING
paramter sharing을 적용한 이전 논문들의 방법에 대해서 언급합니다.
#### 2.3 SENTENCE ORDERING OBJECTIVES
본 논문에서 제안하는 3번째 element 중 하나인 **SENTENCE ORDER PREDICTION (SOP)** 에 대해 설명 합니다. 2 sentence pair 를 학습하는 방법에서, false 예제를 만들어내는 방식에 차이를 둡니다. BERT 는 다른 문서의 문장을 2nd sentence로 사용(NSP)했지만, ALBERT에서는 인접한 두 문장의 order를 swap(SOP)합니다. 자세한 내용은 3장에 다시 언급됩니다.
> ALBERT uses a pretraining loss based on **predicting the ordering of two consecutive segments of text**.
> BERT (Devlin et al.,2019) uses a loss based on **predicting whether the second segment in a pair has been swapped with a segment from another document**.
## 3.THE ELEMENTS OF ALBERT
ALBERT의 main idea를 소개합니다.
## 3.1 MODEL ARCHITECTURE CHOICES
#### Factorized embedding parameterization
BERT와 그 후속 model들에서, WordPices embedding size `$E$`와 hidden layer size `$H$`는 같습니다. 하지만, 이는 modeling이나 실제 구현 측면에서 좋은 선택이 아닙니다.
WordPiece embedding layer의 경우, **context-independent** 한 방식입니다. 그 이후에 쌓이는 Transformer layer는 **context-dependent** 한 layer이며, BERT의 뛰어난 performance는 이 부분에서 나옵니다. 따라서, E와 H를 분리하고 `$H >> E$`가 되도록 setting하는 것이 더 합리적입니다. 또한 vocabulary size `$V$`가 매우 크기 때문에, `$E=H$`의 제한은 성능 향상을 위해, H를 증가시킬 경우, embedding matrix의 size를 매우 크게 만들어 구현을 어렵게 합니다.
ALBERT에서는 이를 위해, one hot vector인 vocabulary `$V$`를 embedding size `$E$`로 mapping 시킨후, 이를 다시 hidden size `$H$`로 mapping하는 방식을 사용합니다. 이를 통해, embedding layer parameter는 83% 감소합니다.
* BERT: `$V\times H\ =\ 23M$`
* ALBERT: `$V\times E(128)\ +\ E\times H\ =\ 4M$`
#### Cross-layer parameter sharing
Parameter sharing은 같은 parameter를 서로 다른 위치에서 사용하는 방법입니다. Parameter sharing은 어는 부분을 sharing 하냐에 따라 다양한 방법이 있지만, ALBERT에서는 Transformer layer 전체를 share 합니다. 이러한 parameter sharing은 parameter 수 자체 감소에도 장점이 있지만, network의 안정화에도 도움이 된다고 합니다. 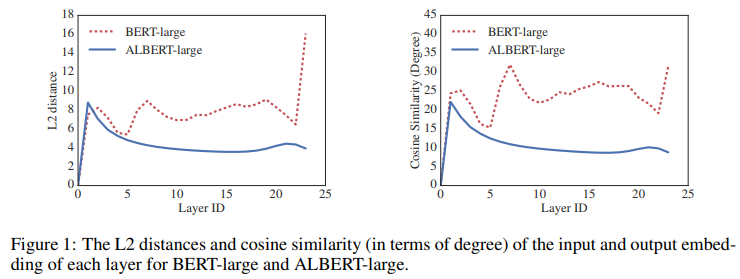
Cross-layer parameter sharing을 Transformer layer에서 parameter는 92%가량 줄였습니다.
* BERT: `$7M\ \times 12\ layers\ =\ 85M$`
* ALBERT: `$7M = 7M$`
#### Inter-sentence coherence loss
Masked Language Modeling(MLM) loss 에 추가하여, BERT에서는 Next-Sentence Prediction(NSP) loss를 사용합니다. 이러한 NSP는 NLI와 같은 downstream task의 성능 향상을 위해 고안되었습니다.
하지만, 이후 연구에서, NSP의 효과가 별로 없는 것처럼 나오는 연구가 있었습니다. 이러한 NSP 비 효율에 대한 원인으로 본논문에서는 **lack of difficulty** 를 들고 있습니다. 다른 document의 sentence를 사용한 NSP는, “topic prediction"과 “coherence prediction” 2 task의 합으로 볼 수 있습니다. “topic prediction"은 “coherence prediction"에 비해 쉬우며, 이 둘다 모두 MLM loss에 포함된다고 되어 있습니다.
> NSP conflates topic prediction and coherence prediction in a single task. However, topic prediction is easier to learn compared to coherence prediction, and also overlaps more with what is learned using the MLM loss.
본 논문에서는 inter-sentence modeling을 위해서, Sentence-Order prediction(SOP)를 사용합니다. SOP를 통해, topic prediction 보다는 inter-sentence coherence를 포커스를 맞출 수 있습니다. 그리고 실험적으로, NSP로 SOP 관련 task를 잘 풀수 없지만, SOP로는 NSP 관련 task를 잘 풀수 있음을 보여줍니다.
### 3.2 MODEL SETUP
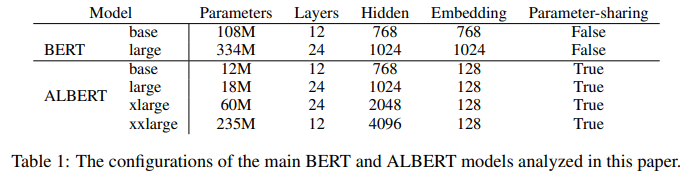 위 table과 같이 같은 hyper parameter에서 ALBERT는 BERT 대비 뛰어난 parameter 감소를 보여 줍니다. 이후 4장 실험에서는 이러한 parameter 감소가 performance 감소로 이어지지 않는 점을 보여줍니다. 결국 ALBERT의 parameter efficiency 향상은 ALBERT-xxlarge와 같은 더 뛰어난 performance를 보여주는 것도 가능하게 합니다.
## 4 EXPERIMENTAL RESULT
### 4.1 EXPERIMENTAL SETUP
BERT에서 사용한 환경을 최대한 따릅니다. 개인적으로 tokenizer로 SentencePiece를 사용한 점입니다. 간단히 tokenizer에 대해서 정리하면 아래와 같습니다.\[[2](https://huggingface.co/transformers/tokenizer_summary.html#tokenizer-summary)]
* BPE(Byte-Pair Encoding): characters 단위에서 시작해서, desired size 가 나올 때까지 merge 합니다. merge의 기준은 나오는 빈도수 입니다.
* WordPiece: BPE와 비슷하지만, merge의 기준이 likelihood의 최대화 입니다. BERT, DistilBERT에서 사용했습니다.
* Unigram: 시작이 BPE, WordPiece와 다르게, corpus에서 시작하여 word를 쪼개서면서 진행합니다. 쪼개는 기준은 loss를 최소화 하는 것입니다.
* sentencePiece: 위에 방법들은 모두 pretokenization을 요구합니다. 하지만 일부 언어에서는 space가 없어 pretokenization이 어렵습니다. sentencePiece에서는 space도 하나의 character로 인지합니다. 이 방법은 de-coding이 쉬워 장점이 되기도 합니다. ALBERT, XLNet에서 setencePiece + unigram을 사용했습니다.
### 4.2 EVALUATION BENCHMARKS
### 4.3 OVERALL COMPARISON BETWEEN BERT AND ALBERT
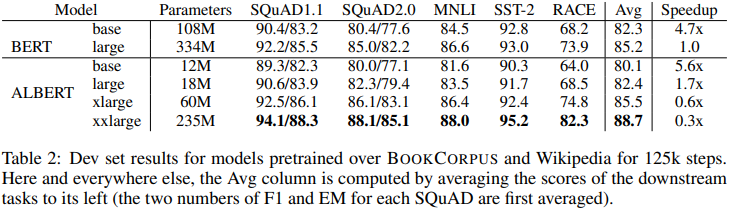 앞 장에서 설명한 parameter efficiency 향상으로, ALBERT-xxlarge는 70%의 parameter로 BERT-large 대비 좋은 성능을 보입니다. 또한, ALBERT의 parameter 감소는 training time에서도 큰 speedup을 보입니다.
### 4.4 FACTORIZED EMBEDDING PARAMETERIZATION
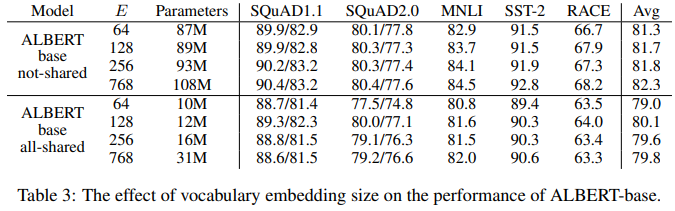 embedding size에 따른 시험에서는, 위에서 한 가설과 같이 큰 차이가 없음을 보입니다. all-sahred case에서 가장 좋은 성능을 보인, 128을 baseline으로 설정하였습니다.
### 4.5 CROSS-LAYER PARAMETER SHARING
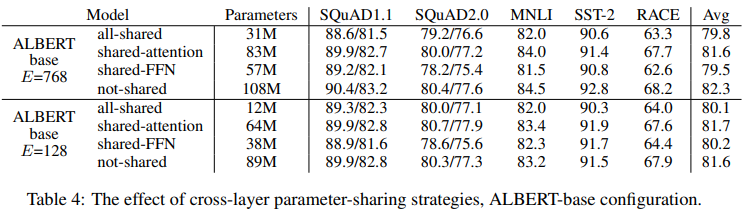 all-shared case에서 performance drop이 나타납니다. 또한 FFN share의 경우, performance drop이 크며, attention share의 경우 performance drop이 낮습니다. 전체적으로 parameter 감소에 비해, performance drop이 크지 않다고 판단하여, all-shared를 default로 선택했습니다.
### 4.6 SENTENCE ORDER PREDICTION (SOP)
 NSP의 경우, SOP task에서 매우 낮은 정확도를 보입니다.(None 보다 낮습니다.) 하지만, SOP의 경우, NSP task에서 유의미한 결과를 보여 줍니다. 결정적으로, downstream task에서 SOP가 평균 1% 정도의 더 좋은 performance를 보입니다.
### 5 DISCUSSION
ALBERT-xxlarge가 less parameter로 BERT-large 보다 좋은 성능을 보였지만, structure의 크기가 크기 때문에 computationally 더 비싼 방법입니다. 이에 따라, training과 imference speed up은 다음 개선의 중요 포인트 지적했습니다. 또한 SOP가 language representation에 있어서 조금 더 좋은 방법이라는 것을 증명했지만, 더 좋은 방법이 있을 거라고 이야기하면서 논문을 끝냈습니다
## Reference
* [BERT-base, 110M parameters](https://github.com/google-research/bert/issues/656#issuecomment-554718760)
* [Tokenizer summary](https://huggingface.co/transformers/tokenizer_summary.html#tokenizer-summary)
* [모델 압축을 위한 기본적인 접근 방법들](https://blog.est.ai/2020/03/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8-%EC%95%95%EC%B6%95-%EB%B0%A9%EB%B2%95%EB%A1%A0%EA%B3%BC-bert-%EC%95%95%EC%B6%95/)